AI 火速复习
你好,这篇博客是为了应试混专业课分数的,这就是初衷。
教材是 《人工智能——一种现代的方法》,第三版
第二章 Agent
Agent 拥有 感知器 和 执行器,感知器用于感知环境(接受数据),执行器用于反作用环境(反馈,函数返回值)
简单反射 Agent
不关注感知历史的 Agent,可以视为函数,接受什么参数就会输出什么值。
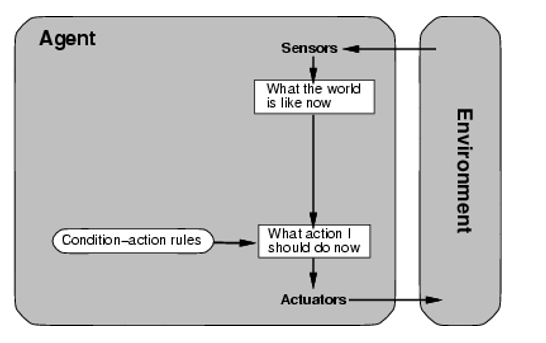
基于模型的反射 Agent
内部还有个 State,记录历史状态,然后根据参数有不同行为。可以视为状态机?
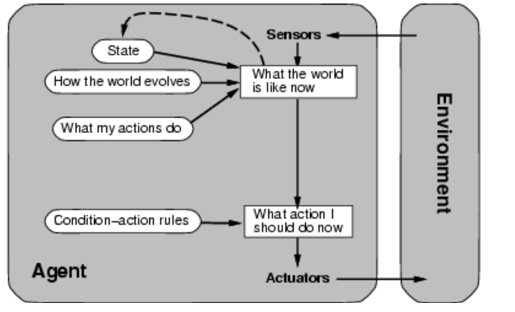
基于目标的 Agent
还需要知道 “我的目标做什么”,然后会有不同的行动
需要结合搜索,规划?
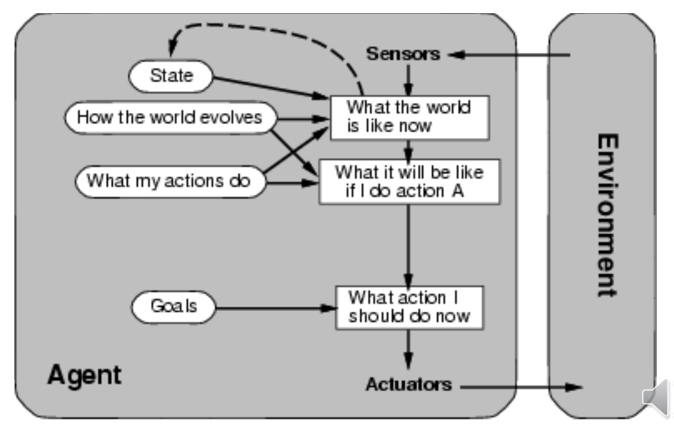
基于效用的 Agent
除了目标以外,还需要考虑达到目标的花销。
这一章好像没什么内容。
第三章 无信息搜索
良定义的问题与其解
良定义问题可以 5 个组成部分形式化描述:
- Agent 初始状态。$In(Arad)$ 返回初始状态。
- Agent 可能行动。${\rm ACTION}(s)$ 返回 $s$ 状态下可以执行的动作集合。
- 转移模型,${\rm RESULT}(s,a)$,返回在状态 $s$ 下执行 $a$ 后达到的状态。
- 目标测试。测试给定的状态是不是目标状态。
- 路径耗散。简单来说就是边权。有时候的算法需要考虑路径耗散的影响。
宽度优先搜索(BFS)
实质上就是对节点进行 FIFO.
一致代价搜索
每次都往路径耗散最小的路径走过去.
一致代价搜索可能是不完备的,也不具备最优性
深度优先搜索(DFS)
实质上就是对节点进行 FILO.
深度受限搜索
在深度优先搜索可能有非常大的搜索深度(甚至无限)时,使用深度受限搜索,达到某个深度值后不再向下而是返回。
迭代加深深度优先搜索
首先假设深度限制为 0,然后进行一次深度受限搜索。如果没有答案则设深度限制为 1,再进行一次,以此类推……
注意只有路径耗散非负的情况下才具有最优性。
第四章 有信息搜索
有信息搜索一般可以叫启发式搜索。
贪心化搜索
给一个估计函数 $G(x)$,$x$ 为状态,返回该状态下到目标节点的估测路径耗散。然后每次都找一个 $G(x)$ 最小的下一状态。
这种算法保证最优性的条件:
- 可采纳性。它不会过高估计到目标的代价。
- 单调性。保证 $cost(n,A)\leq cost(n,n’)+cost(n’,A)$单调性非常重要
,丢失的话应当采用动态规划.
所以这为什么就能保证了
A*搜索
结合贪心化搜索,除了 $H(x)$ 表示当前状态到目标状态的估价以外,还有一个 $G(x)$ 表示搜索到该处已经花费的代价。总估价函数为 $F(x)=G(x)+H(x)$.
爬山法
和另一个梯度下降法只有求局部最大值与局部最小值的区别。
每次都用最优邻居替代。这个邻居取步长 $d$(预设)的。
1 | loop do |
随机重启
因为爬山法对于非单峰函数来说几乎没有最优性,不妨多次随机一个初始状态,重启爬山法,以此避免局部最优解。
模拟退火
模拟退火的流程图: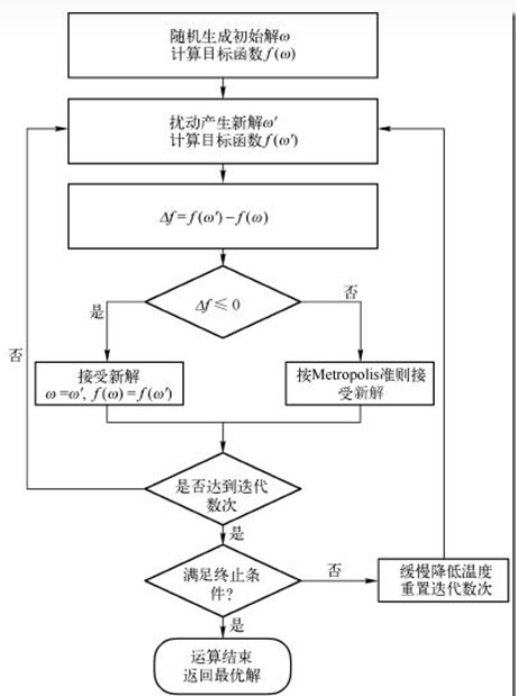
通常,$Metropolis$ 准则即:
计算值 $R=\exp({-\Delta f\over T})$,然后在 $[0,1]$ 内随机一个实数,判断其是否小于 $R$,如果是则接受新解。
伪代码:
1 | while T > minimum_T { |
束搜索
束搜索实际上就是 bfs 的估算版本。
局部束:选取 $k$ 个最佳的后继状态,而不是全部后继状态。
随机束:随机选取 $k$ 个后继状态。
遗传算法
产生 $k$ 个初始状态,然后计算每个状态的健康度 $H(x)$。再根据健康度计算它接下来被选取的概率 (健康度更高的概率更大,以此趋于优解),即$P(H(x))$. 然后根据概率加权随机选取两个状态。
选取后随机选取杂交点杂交,再以一定概率随机变异,产生后代,以此迭代。
第五章 对抗搜索
极小极大算法
向下思考 $N$ 步构建决策树(暴力),通过贪心策略从下往上回溯。
α-β 剪枝
从下往上考虑时,剪去不可能的位置。例如现在节点 $P$ 执行 $MAX$ 操作,已经得出一个值 $x_1$,则其他所有将得出值 $x\leq x_1$ 的都没有意义了,于是剪去。
博弈树搜索优化
评估函数,用以计算当前位置的有效性。
评估函数的定义准则:
对于终止状态的排序应该和效用函数一致
计算时间不能太长
对于非终止状态应该和取胜几率相关
评估函数只适用于不会出现大摇摆的棋局。(?)
截断搜索,进行资源限制,限制递归深度。
- 前向剪枝,直接剪去一些子树。
- Probcut?
- 查表。开局和结尾的可能性有限,可以提前打表并查表。
随机博弈
例如飞行棋,西洋陆棋,除了 $MAX,MIN$ 角色的节点以外还要包括随机节点。随机节点的连接给出一个概率权值,计算贡献时求加权期望即可。
部分可观察博弈
信念状态,随机部分可观察,概率推算
…
第六章 约束满足问题 (CSP)
定义
状态空间:为一系列变量和其赋值的笛卡尔积。
目标测试:是否赋值完成,是否满足约束条件。
例如,求一个具有某种性质的排列、染色问题。
CSP 问题的三个部分:
变量、值域、约束集合。
回溯搜索求解 CSP
需要规定赋值顺序(决定值域顺序也是好的)。要提高效率,可以:
- 根据条件在更浅的节点就判断是否合法,提前回溯
- 最少约束值:选择使剩余变量赋值空间更大的值更可能达到合法结果
- 约束最多变量:优先选择最能约束其他变量的变量(参与的非全局约束最多)
- 最受约束变量:选择剩余可赋值最少的变量赋值。
- 前向检验:提前向未赋值变量传递约束信息
- 智能回溯:建立冲突集合。
第七章 逻辑 Agent
语法、语义中一些没见过的表达式和名词
$\alpha$ 的所有模型. 可以认为就是实例全集.
模型检验:枚举所有可能模型来检验断言 $\alpha$ 是否为真.
表示 $\alpha$ 蕴含 $\beta$,即 $\alpha \Rarr \beta$.
有效:一个语句在考虑的模型集合中恒为真.
可满足:一个语句在考虑的模型集合中存在其为真的模型.
不可满足:在给定的模型集合中恒为假.
知识库
首先,需要构建一些命题词,例如 Wumpus 游戏中的:

定理证明
真值表枚举(模型检验)
时间复杂度 $O(2^n)$.
逻辑等价
如果两个语句 $\alpha,\beta$ 在同一个模型中同真同假,可以认为 $\alpha \equiv \beta$. 这也意味着它们互相蕴含。
推导和证明
表示只要有 $\alpha \Rarr \beta$ 和 $\alpha$ 同时成立,就能推出 $\beta$,而无关 $\alpha$ 与 $\beta$ 的形式。
归结推理
第八章 一阶逻辑
和命题逻辑没啥区别,主要还是记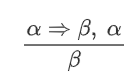 这个式子。
这个式子。
前向链接算法
从原子语句出发,应用假言推理增加新的原子语句,直到不可再推理。
优化方法:
增量前向链接:每个第t次迭代推理出来的新事实应该由至少一个第t-1次迭代中推理出来的新事实导出。因此,在第t次迭代时,只检查那些规则前提包含了能与第t-1次迭代新推理出的事实进行合一的合取子句
不相关事实:产生许多与目标毫无关系的事实(用反向链接算法解决)
反向链接
通过一个推理出的原子语句反向推出其成立需要满足的条件。
第十章 不确定性量化
逻辑理论无法处理不确定性问题,因为
惰性(确保规则完全严格的计算量巨大)
理论的无知(缺乏理论支撑)
实践的无知(所有必要的测试并没有全部完成,甚至存在无法进行的测试)
概率理论下的 Agent 约束
本体约束:和逻辑 Agent一致,由成立与不成立的事实。
认识约束:逻辑 Agent 只认为语句为正确和错误,而概率 Agent 会有一个 $[0,1]$ 间的实数作为信念度。信念度也可以认为是其为真的概率。
概率 Agent 的决策理论:总是使期望效用最大化。
完全联合分布:对应真值表,即取各个值的概率。
先验概率:不需要条件的概率
后验概率:条件概率
记一下条件概率公式。
第十一章 贝叶斯网络
书上说,贝叶斯网络是一种数据结构。可以表示任何完全联合概率分布。
特征:
- 是个有向图。
- 每个节点对应一个随机变量。
- 每个节点有一个条件概率分布,量化父节点对该节点的影响。
啥意思呢?
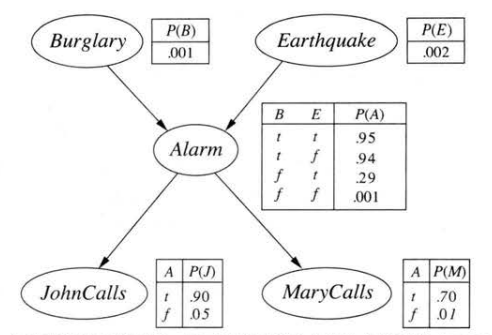
如图,列父节点的真值表,对应子节点的各个概率。总之每个节点给出变量的同时还要给出其分布。
枚举精确推理
枚举出所有可能,计算每个可能的概率,加和得到事件概率
近似推理
直接采样法
根据已知概率分布生成样本,采样得到事件的近似概率。
拒绝采样法
用法:用于计算比较难得到的条件概率。用一种易于采样的分布,为一个难以采样的分布生成采样样本。
做法:根据先验分布生成样本,拒绝掉所有与证据不匹配的样本
缺点:拒绝太多样本
似然加权法
固定证据变量的值,然后只对非证据变量采样。
Gibbs 采样法